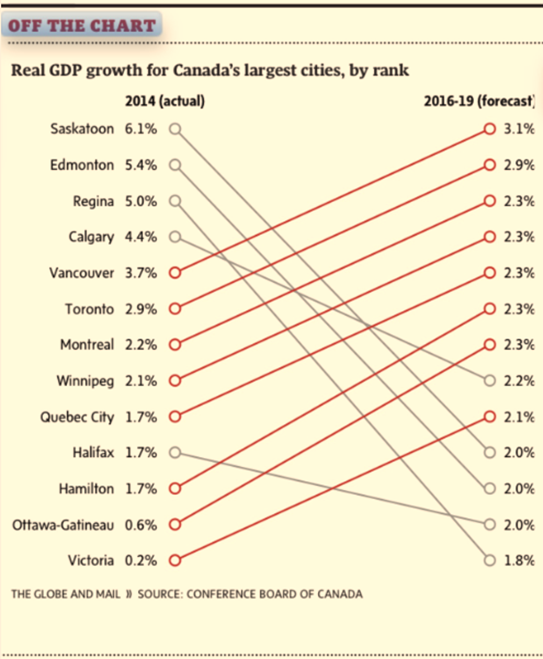
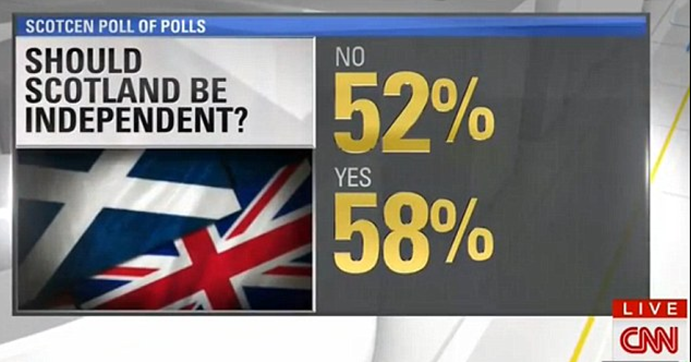
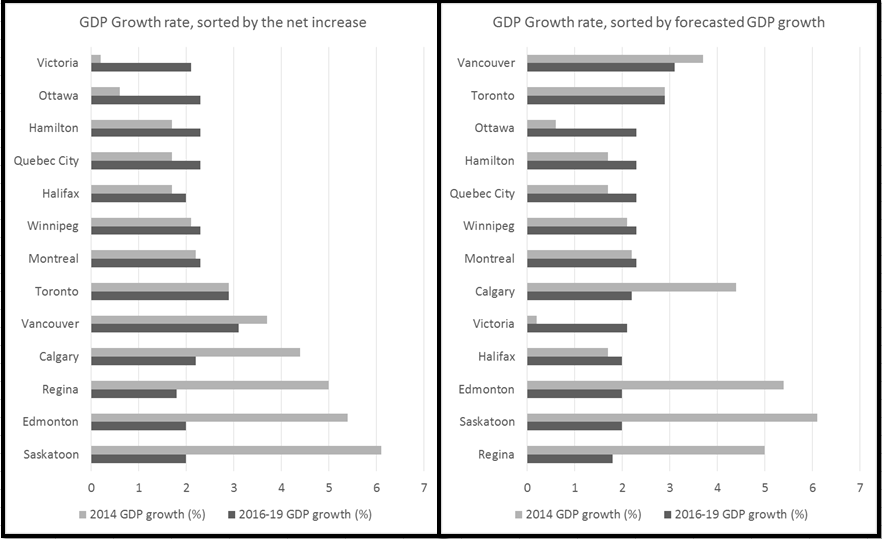
In the world of big data and real-time analytics, Microsoft users are still living with the constraints of the bygone days of little data and basic numeracy.
If you happen to use Microsoft Excel for running Regressions, you will soon realize your limits: The Windows version of Excel 2013 permits no more than 16 explanatory variables.

Excel has made great progress in expanding its capabilities in the recent past. Unlike the few thousand rows in the past, the current version permits about a million rows per Sheet (a single data set). But when it comes to regression, you may have several thousand observations in the data set, you are still limited by a hard constraint of sixteen explanatory variables.
Some would argue that for parsimony, we should be content with the restriction. True, but with categorical variables, the number of explanatory variables stretch beyond the artificial constraints set by Microsoft Excel.
Others might inquire why do statistical analyses in Excel in the first place. Despite the inherent limitations in Microsoft Excel, business schools in particular and other social science undergraduate programs in general, are increasingly turning to Excel to teach courses in statistics. If you were to take a quick look at the curriculum of the undergraduate business and numerous MBA programs, you would realize how widespread is the use of Excel for courses in statistics and analytics.
At Ryerson University, I switched to R years ago for my MBA courses. Thanks to John Fox’s R Commander, the transition to R was without much hassle. The students were told in the very beginning that they were now part of the big league, and hiding behind spreadsheets was no longer an option.
I must mention that Microsoft Excel continues to be my platform of choice for a variety of tasks. I use Excel several times a day, but not for statistical analysis. I am not suggesting that Excel cannot do statistics; I am arguing that it can do a much better job of it.
As I see it, Microsoft has several options. First is do nothing. After all, Microsoft Excel has no real competition in the Windows environment. Second, it could turn to the team that has programmed the linest function in Excel and ask them to add some muscle to it. That will be the wrong approach.
Instead, Microsoft should explore ways to integrate R or another freeware with Excel to add a complete analytics menu. Microsoft should learn from what the leaders in analytics are already doing. SPSS, an industry leader in analytics category, has already integrated R, allowing the SPSS users to merge the robust data management strengths of SPSS with the state-of-the-art analytics bundled with R. SAS, another big name in analytics, is about to do the same.
And since Microsoft has recently acquired Revolution R, it makes even more sense to build a bridge between Excel and Revolution R Open (RRO).
R Through Excel is one example of integrating R with Excel. If Microsoft were to put its weight behind the initiative, it could build a seamless coupling with R expanding the analytic capabilities for hundreds of million Excel users.
As for the SPSS, I recommend they also consider another option. If Microsoft were to integrate RRO with Excel, they could acquire an advanced analytics software and integrate it with SPSS. For this option, I would recommend Limdep, which I have found to be the most diverse software for statistical analysis and econometrics. Even though R is a collective effort of thousands of software developers, Limdep offers numerous routines and post-estimation options that are not available in the thousands of R packages. SPSS integrated with Limdep could become the most diversely capable commercial software in the market as it will bridge the gap with SAS and Stata.
As for the colleagues in business faculties pondering over what platform to adopt for the analytics/software courses, I would say know your limits, especially with Microsoft Excel while deciding upon the curriculum.
If you happen to use Microsoft Excel for running Regressions, you will soon realize your limits: The Windows version of Excel 2013 permits no more than 16 explanatory variables.

Excel has made great progress in expanding its capabilities in the recent past. Unlike the few thousand rows in the past, the current version permits about a million rows per Sheet (a single data set). But when it comes to regression, you may have several thousand observations in the data set, you are still limited by a hard constraint of sixteen explanatory variables.
Some would argue that for parsimony, we should be content with the restriction. True, but with categorical variables, the number of explanatory variables stretch beyond the artificial constraints set by Microsoft Excel.
Others might inquire why do statistical analyses in Excel in the first place. Despite the inherent limitations in Microsoft Excel, business schools in particular and other social science undergraduate programs in general, are increasingly turning to Excel to teach courses in statistics. If you were to take a quick look at the curriculum of the undergraduate business and numerous MBA programs, you would realize how widespread is the use of Excel for courses in statistics and analytics.
At Ryerson University, I switched to R years ago for my MBA courses. Thanks to John Fox’s R Commander, the transition to R was without much hassle. The students were told in the very beginning that they were now part of the big league, and hiding behind spreadsheets was no longer an option.
I must mention that Microsoft Excel continues to be my platform of choice for a variety of tasks. I use Excel several times a day, but not for statistical analysis. I am not suggesting that Excel cannot do statistics; I am arguing that it can do a much better job of it.
As I see it, Microsoft has several options. First is do nothing. After all, Microsoft Excel has no real competition in the Windows environment. Second, it could turn to the team that has programmed the linest function in Excel and ask them to add some muscle to it. That will be the wrong approach.
Instead, Microsoft should explore ways to integrate R or another freeware with Excel to add a complete analytics menu. Microsoft should learn from what the leaders in analytics are already doing. SPSS, an industry leader in analytics category, has already integrated R, allowing the SPSS users to merge the robust data management strengths of SPSS with the state-of-the-art analytics bundled with R. SAS, another big name in analytics, is about to do the same.
And since Microsoft has recently acquired Revolution R, it makes even more sense to build a bridge between Excel and Revolution R Open (RRO).
R Through Excel is one example of integrating R with Excel. If Microsoft were to put its weight behind the initiative, it could build a seamless coupling with R expanding the analytic capabilities for hundreds of million Excel users.
As for the SPSS, I recommend they also consider another option. If Microsoft were to integrate RRO with Excel, they could acquire an advanced analytics software and integrate it with SPSS. For this option, I would recommend Limdep, which I have found to be the most diverse software for statistical analysis and econometrics. Even though R is a collective effort of thousands of software developers, Limdep offers numerous routines and post-estimation options that are not available in the thousands of R packages. SPSS integrated with Limdep could become the most diversely capable commercial software in the market as it will bridge the gap with SAS and Stata.
As for the colleagues in business faculties pondering over what platform to adopt for the analytics/software courses, I would say know your limits, especially with Microsoft Excel while deciding upon the curriculum.